关联对象嵌套序列化
如果需要序列化的数据中包含有其他关联对象,则对关联对象数据的序列化需要指明。
例如,在定义人物数据的序列化器时,外键book(即所属的图书)字段如何序列化?
我们先定义PeopleInfoSerialzier除外键字段外的其他部分
class PeopleInfoSerializer(serializers.Serializer):
"""英雄数据序列化器"""
id = serializers.IntegerField(label='ID')
name = serializers.CharField(label='名字')
password=serializers.CharField(label='密码')
description = serializers.CharField(label='描述信息')
对于关联字段,可以采用以下几种方式:
1) IntegerField
需求数据
{'id': 10, 'book_id': 3, 'description': '独孤九剑', 'gender': 1, 'name': '令狐冲'}
此字段将被序列化为关联对象的主键。
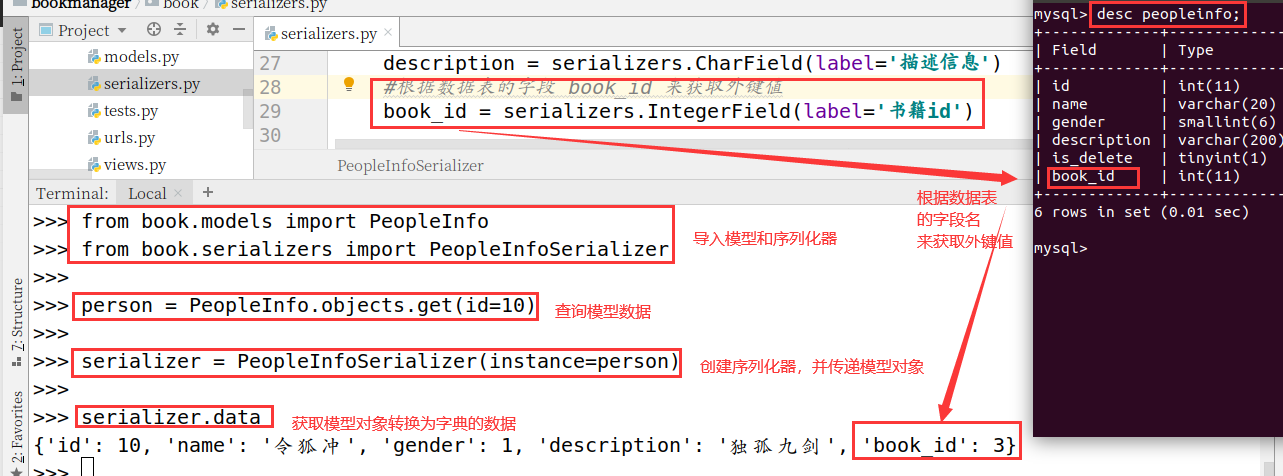
book_id = serializers.IntegerField(label='书籍id')
使用效果:
>>> from book.models import PeopleInfo
>>> from book.serializers import PeopleInfoSerializer
>>> person = PeopleInfo.objects.get(id=10)
>>> serializer = PeopleInfoSerializer(instance=person)
>>> serializer.data
{'id': 10, 'book_id': 3, 'description': '独孤九剑', 'gender': 1, 'name': '令狐冲'}
2) PrimaryKeyRelatedField
需求数据
{'id': 10, 'book': 3, 'description': '独孤九剑', 'gender': 1, 'name': '令狐冲'}
此字段将被序列化为关联对象的主键。
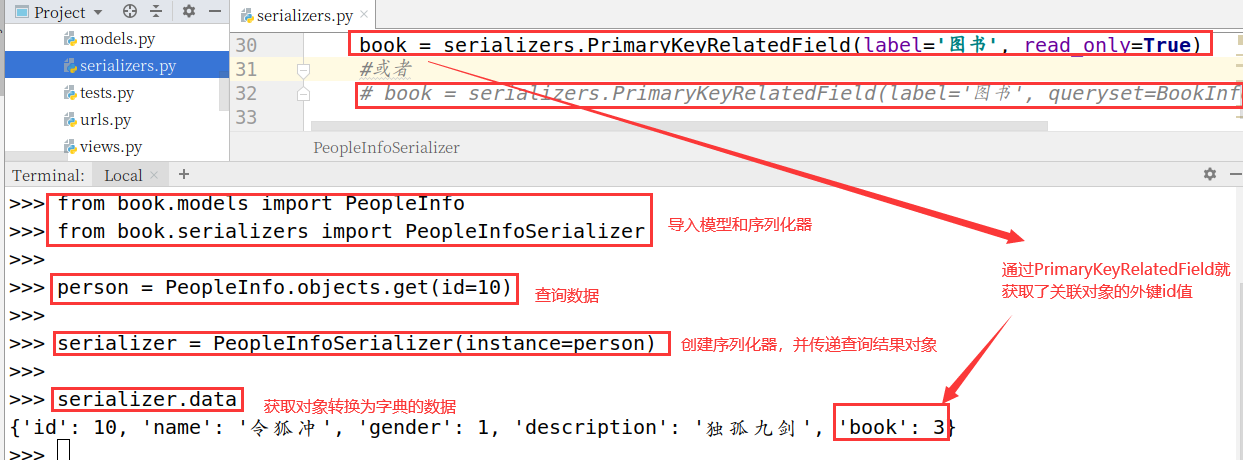
book = serializers.PrimaryKeyRelatedField(label='图书',read_only=True)
#或者
book = serializers.PrimaryKeyRelatedField(label='图书',queryset=BookInfo.objects.all())
指明字段时需要包含read_only=True或者queryset参数:
- 包含read_only=True参数时,该字段将不能用作反序列化使用
- 包含queryset参数时,将被用作反序列化时参数校验使用
使用效果:
>>> from book.models import PeopleInfo
>>> from book.serializers import PeopleInfoSerializer
>>> person = PeopleInfo.objects.get(id=10)
>>> serializer = PeopleInfoSerializer(instance=person)
>>> serializer.data
{'id': 10, 'book': 3, 'description': '独孤九剑', 'gender': 1, 'name': '令狐冲'}
3) StringRelatedField
需求数据
{'description': '独孤九剑', 'name': '令狐冲', 'gender': 1, 'book': '笑傲江湖', 'id': 10}
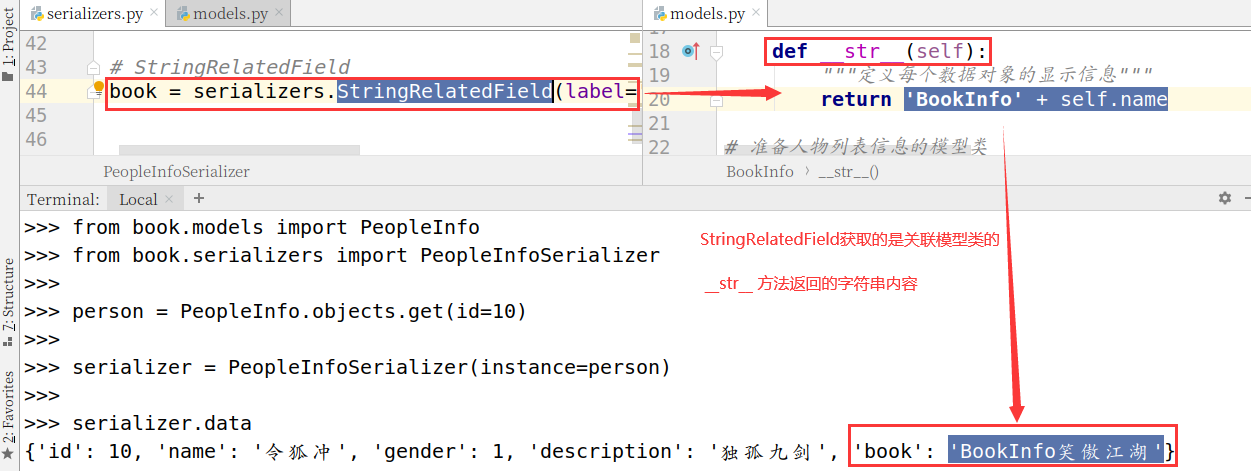
此字段将被序列化为关联对象的字符串表示方式(即__str__方法的返回值)
book = serializers.StringRelatedField(label='图书')
使用效果
>>> from book.models import PeopleInfo
>>> from book.serializers import PeopleInfoSerializer
>>> person = PeopleInfo.objects.get(id=10)
>>> serializer = PeopleInfoSerializer(instance=person)
>>> serializer.data
{'description': '独孤九剑', 'name': '令狐冲', 'gender': 1, 'book': '笑傲江湖', 'id': 10}
问题:如果我写成如下这样,会怎么样?
book = serializers.StringRelatedField(label='图书') book_id = serializers.IntergerField(label='书籍id')
4)使用关联对象的序列化器
需求数据获取书籍以及书籍关联的人物
{
"id": 1,
"name": "射雕英雄传",
"pub_date": "1980-05-01",
"readcount": 12,
"commentcount": 34,
"people": [
{
"id": 1,
"name": "郭靖",
"password": "123456abc",
"description": "降龙十八掌"
},
{
"id": 2,
"name": "黄蓉",
"password": "123456abc",
"description": "打狗棍法"
}
]
}
在BookInfoSerializer中添加关联字段:
from rest_framework import serializers
class PeopleInfoSerializer(serializers.Serializer):
"""英雄数据序列化器"""
id = serializers.IntegerField(label='ID')
name = serializers.CharField(label='名字')
password=serializers.CharField(label='密码')
description = serializers.CharField(label='描述信息')
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID')
name = serializers.CharField(label='名称')
pub_date = serializers.DateField(label='发布日期')
readcount = serializers.IntegerField(label='阅读量')
commentcount = serializers.IntegerField(label='评论量')
#一本书籍关联多个人物
people=PeopleInfoSerializer(many=True)
使用效果
>>> from book.serializers import BookInfoSerializer
>>> from book.models import BookInfo
>>> book=BookInfo.objects.get(id=1)
>>> s = BookInfoSerializer(book)
>>> s.data
>>> {'id': 1, 'name': '射雕英雄传', 'pub_date': '1980-05-01', 'readcount': 12, 'commentcount': 34, 'people': [OrderedDict([('id',('name', '郭靖'), ('gender', 1), ('description', '降龙十八掌')]), OrderedDict([('id', 2), ('name', '黄蓉'), ('gender', 0), ('description']), OrderedDict([('id', 3), ('name', '黄药师'), ('gender', 1), ('description', '弹指神通')]), OrderedDict([('id', 4), ('name', '欧阳锋'),, 1), ('description', '蛤蟆功')]), OrderedDict([('id', 5), ('name', '梅超风'), ('gender', 0), ('description', '九阴白骨爪')])]}